Google Cloud Platform (GCP) 과 TPU 로 한국어 BERT 학습해보기
오늘은 GCP를 활용해서 BERT를 학습시켜보자!
BERT는 tensorflow 버젼을 이용해 학습할 것이다.
(https://github.com/google-research/bert)
BERT를 학습시키기 위한 준비물은 다음과 같다.
1. Large corpus
- 대량의 코퍼스 데이터가 필요하다.
이번 포스팅에서는 결과를 빨리 확인해보기 위해 10,000 라인으로 이루어진 소규모 학습 코퍼스를 사용해보겠다.
2. Vocab
- WordPiece 알고리즘을 이용해 vocab을 얻어내야 한다.
- Vocab 생성은 다음 git 코드를 이용해 만들어낼 수 있다.
(https://github.com/lovit/WordPieceModel/blob/master/wordpiecemodel/bpe.py)
- 영어 버전의 BERT처럼 ' '와 ' _'부분을 '##'으로 변환해줘서 돌렸다.
- Vocab을 생성한 이후, [MASK], [UNK], [SEP], [CLS], [PAD] 를 추가해줘야 문제없이 동작한다!
3. 모델 config 파일
- 모델 학습을 위한 config 파일인데 BERT base 모델을 기준으로 만들어보자.
- BERT git에서 pre-trained BERT 파일을 받으면 거기서 모델 config파일을 얻을 수 있다.
(https://storage.googleapis.com/bert_models/2018_11_03/multilingual_L-12_H-768_A-12.zip)
- 여기 multi lingual 모델의 config 파일 마지막 항목인 vocab_size를 보면, 119547이라고 적혀있는데, 이는 vocab의 크기를 의미한다.
- 따라서, 본인이 만든 vocab에 맞춰 사이즈를 조정해줘야 한다.
먼저 corpus를 학습에 사용할 수 있도록 preprocessing을 해야한다.
Preprocessing 코드는 git에 포함되어 있는 아래 코드를 사용하면 된다.
(https://github.com/google-research/bert/blob/master/create_pretraining_data.py)
한 가지 팁은, input_file의 경우 tf.gfile.GFile 함수로 불러오는데,
한국어의 경우 인코딩 에러가 발생할 수 있다.
그래서 open(input_file, 'r', encoding='utf-8') as reader로 고쳐서 실행하도록 하자!
e.g.)
python3 create_pretraining_data.py --input_file=corpus_mini/sentence_tokenized_dump_wiki_mini.txt --vocab_file=vocabs/vocab_mini.txt --do_lower_case=False --max_seq_length=512 --max_predictions_per_seq=20 --output_file=preprocessed_output/word_word_mini
위 코드대로 돌리면 다음과 같이 코퍼스가 word piece로 변환된는 것을 확인할 수 있으며, output_file 디렉토리에 preprocessed corpus 파일이 떨어져 나온다.
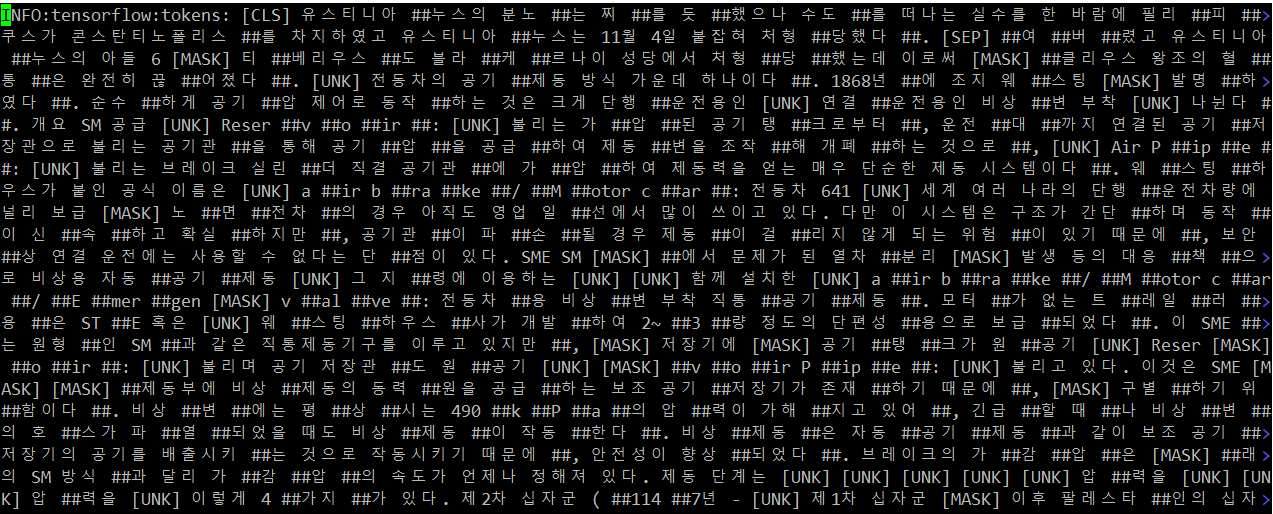
이제 GCP에 해당 corpus와 vocab 파일을 올려서 학습을 수행해보자!
GCP의 사이트는 다음과 같다.
GCP와 G Suite를 포함한 Google Cloud — 무료로 사용해 보기 | Google Cloud
Google Cloud Platform으로 빌드하고 혁신하고 확장하세요. G Suite로 공동작업하고 생산성을 높이세요. Google Cloud로 어떤 가능성을 실현할 수 있는지 알아보세요.
cloud.google.com
여기서 콘솔을 누르면 프로젝트를 생성할 수 있다.

바로 VM을 하나 만들어서 서버 세팅을 해보자!
왼쪽의 텝을 보면 Compute Engine에 VM 인스턴스 라고 하는 항목이 있다.
여기서 새로운 VM을 만들자.
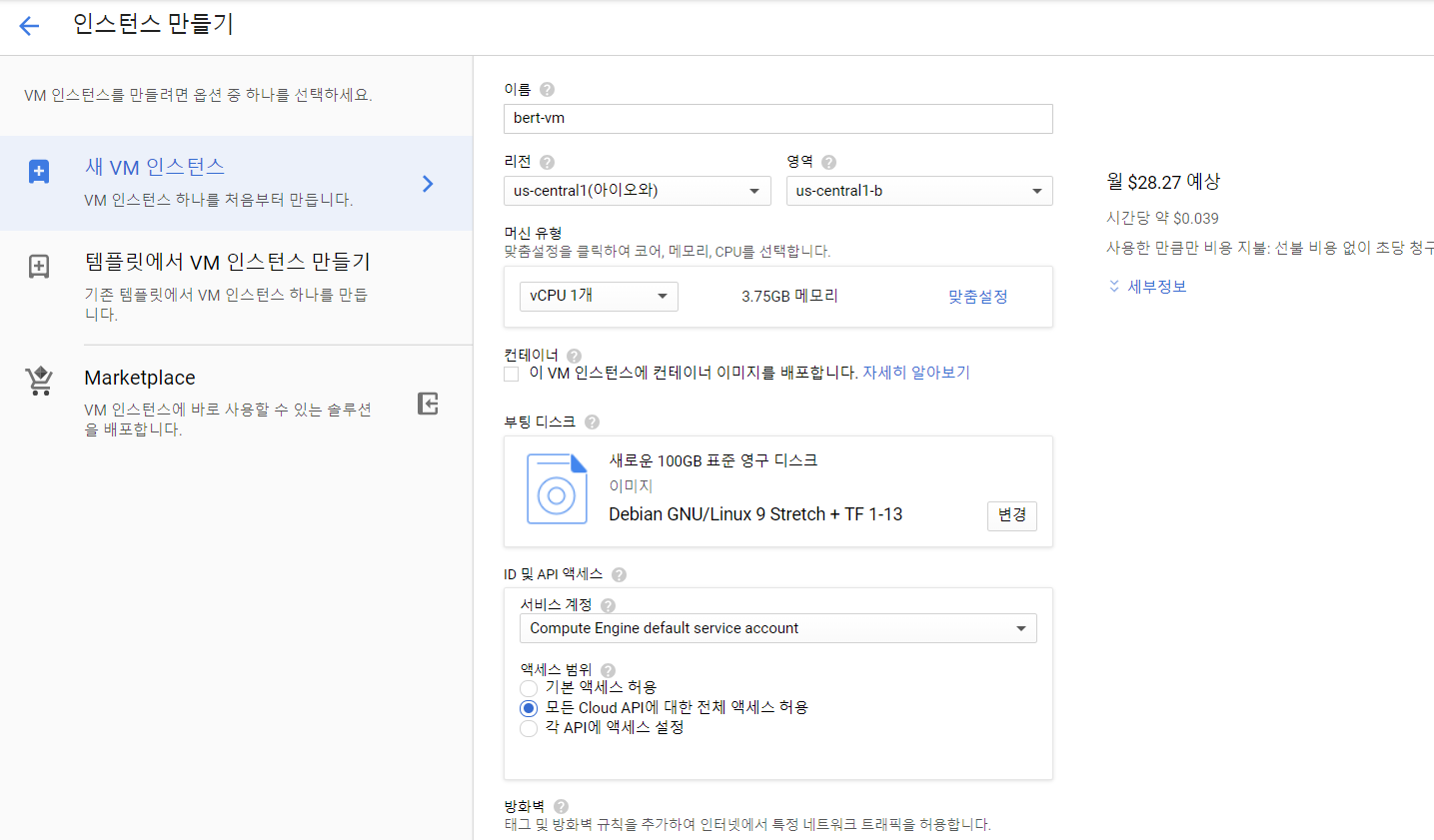
VM을 생성할 때 CPU와 하드디스크를 설정할 수 있는데,
어차피 TPU를 이용해 학습할 예정이니, CPU는 저렴한 모델로 선택했다.
부팅 디스크에는 학습 코퍼스 데이터를 저장해야하니 대충 600GB정도로 설정해주었다.
(참고로 모델은 cloud에 저장되니 학습 코퍼스 사이즈 만큼만 용량을 잡아줘도 된다.)
주의할 점!! 영역을 us-central-b 로 설정해주자!
TPU가 us-east에는 존재하지 않는다!
또한 이미지는
Debian GNU/Linux 9 Stretch + TF 1-13
A Debian linux image with Tensorflow Version 1-13 pre-installed and optimized for Cloud TPUs.
이걸로 설정해주자!!
왜냐하면 tensorflow 설정이 다 되어있기 때문에!
다음으로는 VM에 TPU를 넣어서 연결해보자.
마찬가지로 Compute Engine의 TPU항목을 누르면 TPU를 설정할 수 있다.

TPU 노드를 만들 때 주의할 점은 영역을 위에 만든 VM과 일치시켜줘야 한다는 점이다.
특히, 선점과 비선점에 대한 선택도 중요한데,
선점형의 경우 비용이 더 적지만, 누군가에게 선점당했을 때는 TPU를 사용할 수 없다는 단점이 있다.
난 회사에서 비용을 내주니까 비싼 비선점형으로 돌려볼거다 ^.^

다음은 데이터를 저장할 수 있는 cloud storage를 만들어서 모델이 저장되도록 해보자.
Cloud storage는 Storage텝의 브라우저에서 버킷을 생성할 수 있다.

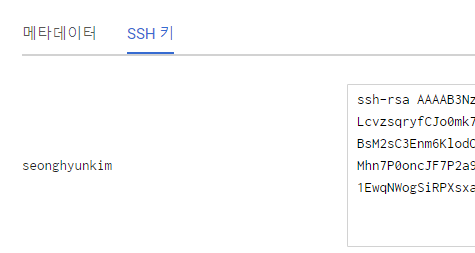
마지막으로 외부에서 우리가 만든 VM에 접속이 가능하도록 ip를 할당받고, 본인의 컴퓨터를 등록해보자!
해당 항목은 Compute Engine > 메타데이터 > SSH 키에서 등록할 수 있다.
SSH 키를 얻는 방법은 아래 블로그에 자세히 설명이 되어있다.
생성된 GCP를 SSH로 접속하기
구글 클라우드 플랫폼(GCP)에 SSH로 접속하는 방법은 1. 브라우저 창에서 열기 2. 맞춤 포트의 브라우저 창에서 열기 3. gcloud 명령 보기 4. 다른 클라이언트 SSH 사용이 있다 현재 사용하고 있는 PC 에서 GCP로..
ruuci.tistory.com
난 리눅스를 이용해 접속할 예정이라, 리눅스에서 ssh-ketgen을 이용해 rsa를 만들어 접속하였다.
만들어진 .pub 파일을 복사해서 붙여넣으면 다음과 같이 SSH가 등록된다.
고정 ip도 할당받아야 하는데, VPC 네트워크 항목의 외부 IP 주소로 가면 유형이 '임시'로 표시되어 있을 것이다.
이걸 '고정'으로 바꿔주면 고정 IP로 할당받을 수 있다.
(리전은 us-central1-b로 되어있을 것이다.)

자! 이제 모든 서버 세팅이 끝났다! :-)
SSH를 통해 접속해보자!
접속에 성공했다~
이제 scp를 통해 데이터를 옮기고, TPU로 학습을 돌려보자.
참고로 GCP를 이용해 VM을 만들면 tensorflow나 TPU 등등 모든 설정이 다 자동으로 되어있어서
git으로 BERT 프로젝트만 받아 실행하면 바로 동작한다.
여기서 학습에 사용되는 데이터들은 모두 cloud storage인 버킷으로 이동을 해줘야한다.
버킷으로 옮기는 방법은 다음과 같다.
gsutil cp -r [옮길 폴더] gs://[버킷주소]
버킷 주소는 Storage > 브라우저 > 버킷 개요에서 확인할 수 있다.

나는 vocab과 preprocessed corpus를 옮겨보도록 하겠다.
gsutil cp -r vocabs/ gs://bert-vocab-mini-bucket
gsutil cp -r preprocessed_output/ gs://bert-vocab-mini-bucket
여기서 주의할 점!
만약 다음과 같이 permission error가 뜬다면?
seonghyunkim@bert-vm:~/bert$ gsutil cp -r vocabs/ gs://bert-vocab-mini-bucket
Copying file://vocabs/vocab_mini.txt [Content-Type=text/plain]...
AccessDeniedException: 403 Insufficient Permission
rm -r ~/.gsutil 명령어를 입력한 후 다시 시도해보자!

이제 BERT 학습을 위한 모든 준비가 끝났다.
아래 명령어를 통해 학습을 돌려보자!
python3 run_pretraining.py \
--input_file=gs://bert-vocab-mini-bucket/preprocessed_output/word_word_mini \
--output_dir=gs://bert-vocab-mini-bucket/output_dir/word_word_mini \
--do_train=True \
--do_eval=True \
--bert_config_file=gs://bert-vocab-mini-bucket/vocabs/bert_config_vocab_mini.json \
--train_batch_size=8 \
--max_seq_length=512 \
--max_predictions_per_seq=20 \
--num_train_steps=1000000 \
--num_warmup_steps=10 \
--learning_rate=1e-4 \
--save_checkpoints_steps=10000 \
--do_lower_case=False \
--use_tpu=True \
--tpu_name=bert-tpu

드디어 학습이 시작됐다 :-)

버킷에도 해당 학습 모델이 잘 저장되는 것을 확인할 수 있었다!
그럼 이만 :-)