한국어로 XLNet 학습해보기!
바로 얼마 전! BERT의 성능을 한참 뛰어넘는 XLNet 모델에 대한 논문과 코드가 공개되었다.
자세한 논문과 알고리즘은 차근차근 공부하기로 하고, 오늘은 무작정 XLNet 학습을 시도해보도록 하자 :-)
먼저 XLNet의 git에 들어가서 git을 clone해온다.
https://github.com/zihangdai/xlnet
zihangdai/xlnet
XLNet: Generalized Autoregressive Pretraining for Language Understanding - zihangdai/xlnet
github.com
XLNet을 학습하려면 3가지의 과정을 거쳐야 한다.
1. Sentencepiece model 생성
2. 학습 데이터의 데이터화
3. 학습!
여기서 1번을 수행하기 전에 학습 코퍼스의 전처리 과정이 요구된다!
보통은 문서 구분이 없는 large corpus를 학습 데이터로 사용할 텐데, XLNet을 사용하기 위해선 학습 데이터를 문서 단위로 구분을 해줘야 한다.
이 때, 문서 구분은 이중 엔터, 혹은 <eod> tag를 넣음으로써 구분될 수 있다.
또한, 하나의 문서 안에서 paragraph가 분리될 때는 <eop> tag를 넣어 구분된다.
여기선 언제나 유용한 wiki 한국어 dump data를 이용해 전처리를 진행해보도록 하자 :-)
먼저 wiki dump data의 raw text를 다운받는다.
다운로드는 구글에 검색하면 쉽게 받을 수 있을 것이다 :-)
나는 예전에 논문을 쓰기 위해 받았던 2016년 09월 wiki data가 있어서 이걸로 학습해보도록 하겠다.

Wiki dump의 경우, wiki extractor를 이용해 텍스트만을 뽑아 전처리가 가능하다! :-)
나는 https://github.com/attardi/wikiextractor 사이트에서 WikiExtractor.py를 수정하여 데이터를 구축하였다.
구축 규칙은 먼저 제목을 모두 없앴고, 문서와 문서 사이는 2줄의 엔터를 넣어서 구분하도록 하였다 :-)
또한 하나의 문서 안에 <eop> tag를 넣어서 paragraph가 분리되었음을 표기해주었다.

참고로 wiki dump의 경우, 문장 분리가 이루어지지 않아 있는 경우가 많은데, 형분석기나 문장 분리기를 쓰기는 너무 과한 것 같아서 nltk의 sent_tokenize()를 이용해 분리만 하였다.
Natural Language Toolkit — NLTK 3.4.3 documentation
www.nltk.org
이렇게 편집을 하고 나면 대충 550만 문장, 4000만 단어 정도의 코퍼스가 만들어진다!
뭐, 엄청 큰 코퍼스는 아니지만, 이정도로도 학습 테스트를 하기엔 충분하지 않을까?
학습을 위해 먼저 sentencepiece model을 만들어보자 :-)
Sentencepiece model을 만드는 과정은 아래 git 문서를 통해 설명되어 있다.
https://github.com/google/sentencepiece
google/sentencepiece
Unsupervised text tokenizer for Neural Network-based text generation. - google/sentencepiece
github.com
C++과 python을 활용하는 방법이 있는데, 나는 python module을 설치해서 만들어보도록 하겠다 :-)
sentencepiece python module은 다음의 명령어를 통해 설치할 수 있다.
% pip install sentencepiece
그리고 python을 켜서 다음과 같이 입력하자!
import sentencepiece as spm
spm.SentencePieceTrainer.train('--input=wiki_00 --model_prefix=sp10m.cased.v3 --vocab_size=70000 --character_gram --control_symbols=<cls>,<sep>,<pad>,<mask>,<eod> --user_defined_symboles=<eop>,.,(,),",-,_,£,€ --shuffle_input_sentence --input_sentence_size=5000000')
vocab_size의 경우 내 맘대로 (이유없이) 그냥 7만으로 정했다 :-)
사실 ETRI의 BERT를 보면 vocab size가 3만정도인 것으로 봐서, vocab이 3만개여도 충분하게 잘 학습이 되는 것 같다.
이렇게 하면 몇 분 안걸려서 다음과 같이 모델이 저장되었다는 메세지가 출력된다.
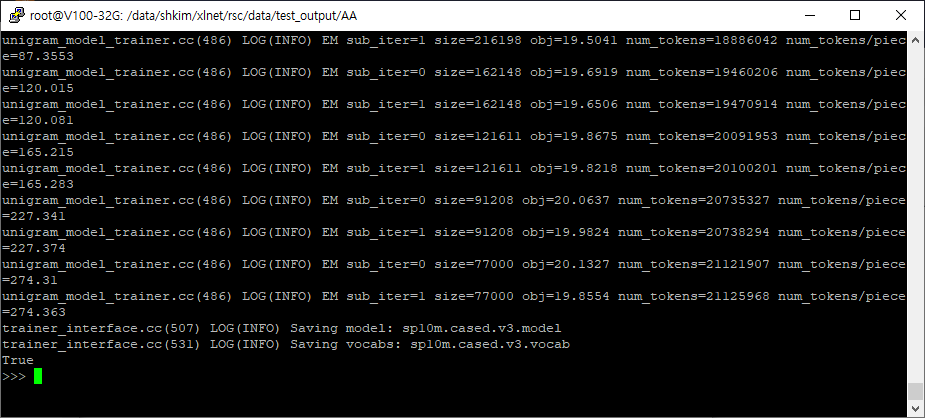
Python 코드를 실행한 디렉토리를 확인하면, 모델과 vocab이 저장된 것을 확인할 수 있다! :-)
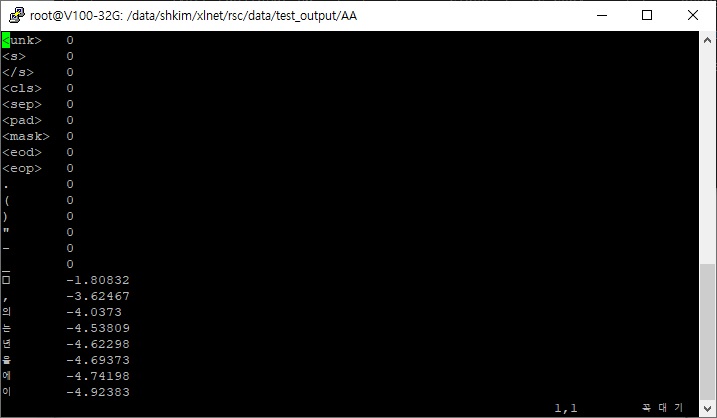
정확히 7만개의 vocab이 저장되었다.
이제 학습 코퍼스를 전처리 후 학습 가능한 데이터로 변환시켜보자! :-)
XLNet의 data_utils.py를 사용하면 바로 변환이 가능하다.
해당 소스코드를 다음과 같이 실행해보자.
python data_utils.py \
--bsz_per_host=32 \
--num_core_per_host=16 \
--seq_len=512 \
--reuse_len=256 \
--input_glob=rsc/data/test_output/AA/wiki_00 \ <- 코퍼스 텍스트 파일
--save_dir=rsc/preprocessed_output \
--num_passes=20 \
--bi_data=True \
--sp_path=rsc/data/test_output/AA/sp10m.cased.v3.model \ <- 앞서 만든 sentencepiece 모델 파일
--mask_alpht=6 \
--mask_beta=1 \
--num_predict=85
이렇게 실행하면 파일을 읽으며 변환을 시켜준다 :-)
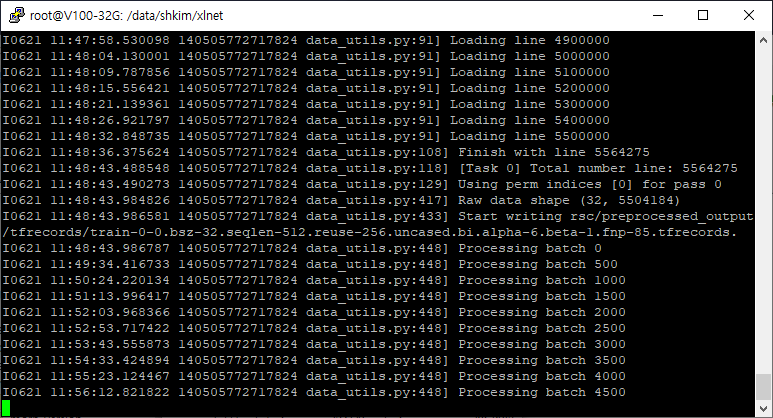
이 과정은 상당히 오래걸린다 :-)
대략 한 40분 정도 소요된 것 같다.
이 시간이 지나면 학습 데이터가 만들어지고, 드디어 xlnet을 학습해볼 수 있다!
(※반드시 corpus_info.json 과 log를 확인하여 디렉토리나 vocab_size 등이 알맞게 기입되어 있는지 확인하도록 하자!!)
python train_gpu.py \
--corpus_info_path=rsc/preprocessed_output/corpus_info.json \
--record_info_dir=rsc/preprocessed_output/tfrecords \
--train_batch_size=32 \
--seq_len=512 \
--reuse_len=256 \
--perm_size=256 \
--n_layer=24 \
--d_model=1024 \
--d_embed=1024 \
--n_head=16 \
--d_head=64 \
--d_inner=4096 \
--untie_r=True \
--mask_alpha=6 \
--mask_beta=1 \
--num_predict=85 \
--model_dir = model_output/model \
이렇게 돌리고 나면?

성공적으로 학습이 시작된다!! :-)
이제 누군가 한국어 버젼 xlnet을 만들어 공개하기를 기다리면 된다 ^^..
ps. wiki dump 버젼의 XLNet 결과는 학습 이후 이 포스팅에 업데이트 할 예정이다 :-)