Feature normalization은 feature scailing이라고도 불리우며, 데이터의 feature나 독립변수의 구간을 표준화하는 방법론이다.
이를 통해 데이터 feature 사이의 차원 영향을 제거하는 것을 목적으로 한다.
예를 들어, 사람의 키는 일반적으로 1.6-1.8 m 수치 범위를 가지고, 몸무게는 50-100 kg의 수치 범위를 가지기 때문에,
두 feature가 서로 다른 범위에 있어서 특정 feature에 bias될 수 있을 가능성이 있다.
수치형 데이터에 대한 정규화 방식은 크게 두 가지가 있다.
1. 선형 함수 정규화 (min-max normalization)
- 결과 값이 [0-1]에 투영되도록 만든다, 데이터를 동일한 비율로 축소하거나 확대한다.
import random
datas = []
for i in range(0, 100):
datas.append(random.randrange(70, 100))import matplotlib.pyplot as plt
plt.hist(x=datas, bins='auto')
plt.xlim(0, 100)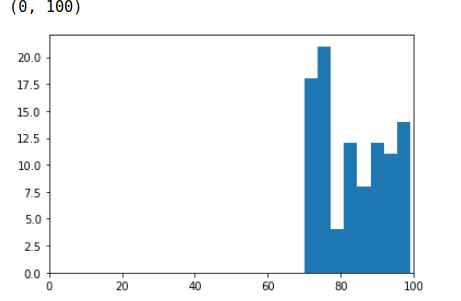
위 히스토그램 결과와 같이, 데이터가 현재 [70-100] 범위 내에 편향되어 있는 것을 볼 수 있다.
선형 정규화의 공식은 아래와 같이 표현할 수 있다.

max_num = max(datas)
min_num = min(datas)
normalized_datas = []
for data in datas:
normalized_data = (data - min_num) / (max_num - min_num) # 선형함수 정규화 공식
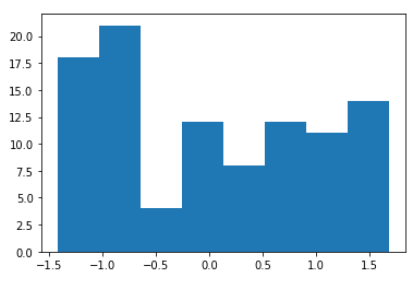
normalized_datas.append(normalized_data)plt.hist(x=normalized_datas, bins='auto')
plt.xlim(0, 1)
위 함수를 거치면 데이터가 [0-1] 사이로 정규화가 이루어진다.
2. 표준 정규화 (z-score normalization, standard scailing)
- 데이터를 평균이 0이고, 표준편차가 1인 분포상으로 투영한다.

import statistics
mean_num = statistics.mean(datas)
std_num = statistics.stdev(datas)
normalized_datas = []
for data in datas:
normalized_data = (data - mean_num) / std_num
normalized_datas.append(normalized_data)plt.hist(x=normalized_datas, bins='auto')
정규화를 수행하기 전에는 log scailing으로 변환을 한 후에 하는 것이 좋다.
Log scailing 행위는 skewed 되어있는 데이터의 왜곡을 줄이기 위한 작업이 될 수 있다.
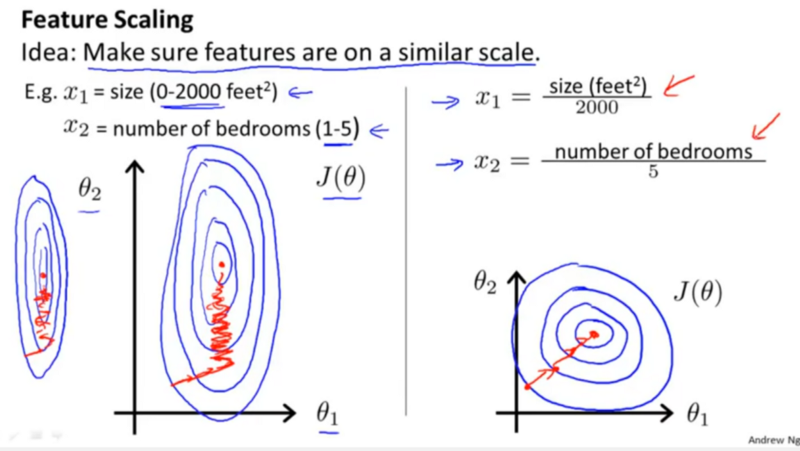
수치형 데이터의 정규화가 필요한 이유는, 경사 하강법을 더 빠른 속도로 수행하는데 중요하다.
'Machine Learning > Basic' 카테고리의 다른 글
| 성능 평가 지표 (0) | 2020.07.27 |
|---|---|
| Categorical Feature (0) | 2020.07.25 |
| Natural Language Representations (0) | 2020.07.15 |

