자연어는 대표적인 비정형 데이터 중 하나이다. 자연어를 데이터로써 표현하는 방법은 기계학습 영역에서 아주 중요한 위치를 차지하고 있다.
1. Back of words (BOW)
- BOW는 가장 기초적인 텍스트 표현 모델이다. 이는 각 텍스트를 순서에 상관없이 단어 단위로 나눠 (tokenizing) 한 가방 안에 담는 방식이다.
텍스트 내에서 특정 단어가 n번 등장했다면, 이 가방에는 그 특정 단어가 n개 있게 된다.
또한, 가방을 흔들어서 단어를 섞었기 때문에, 단어의 순서는 중요해지지 않는다.
sent1 = 'John likes to watch movies . Mary likes movies too .'
sent2 = 'Mary also likes to watch football games .'tokenized_sent1 = sent1.split(' ')
tokenized_sent2 = sent2.split(' ')
print(tokenized_sent1)
print(tokenized_sent2)>> ['John', 'likes', 'to', 'watch', 'movies', '.', 'Mary', 'likes', 'movies', 'too', '.']
['Mary', 'also', 'likes', 'to', 'watch', 'football', 'games', '.']
word2idx={}
bow=[]for token in tokenized_sent1:
if token not in word2idx:
word2idx[token] = len(word2idx)
bow.append(1)
else:
word_idx = word2idx[token]
bow[word_idx] += 1
for token in tokenized_sent2:
if token not in word2idx:
word2idx[token] = len(word2idx)
bow.append(1)
else:
word_idx = word2idx[token]
bow[word_idx] += 1print('vocabs:', word2idx)
print(bow)>> vocabs: {'John': 0, 'likes': 1, 'to': 2, 'watch': 3, 'movies': 4, '.': 5, 'Mary': 6, 'too': 7, 'also': 8, 'football': 9, 'games': 10}
[1, 3, 2, 2, 2, 3, 2, 1, 1, 1, 1]
두 번째 출력 문은 만들어진 BOW이다.
즉, 각 차원은 vocab에 정의된 단어 idx와 일치하고, 각 차원의 가중치는 해당 단어가 문장에서 얼마나 중요한지 나타낸다.
위 문서에서는 [likes, .] 가 3의 가중치로 중요도를 가진다.
일반적으로는 BOW의 가중치를 표현할 때, TF-IDF 값을 이용한다.
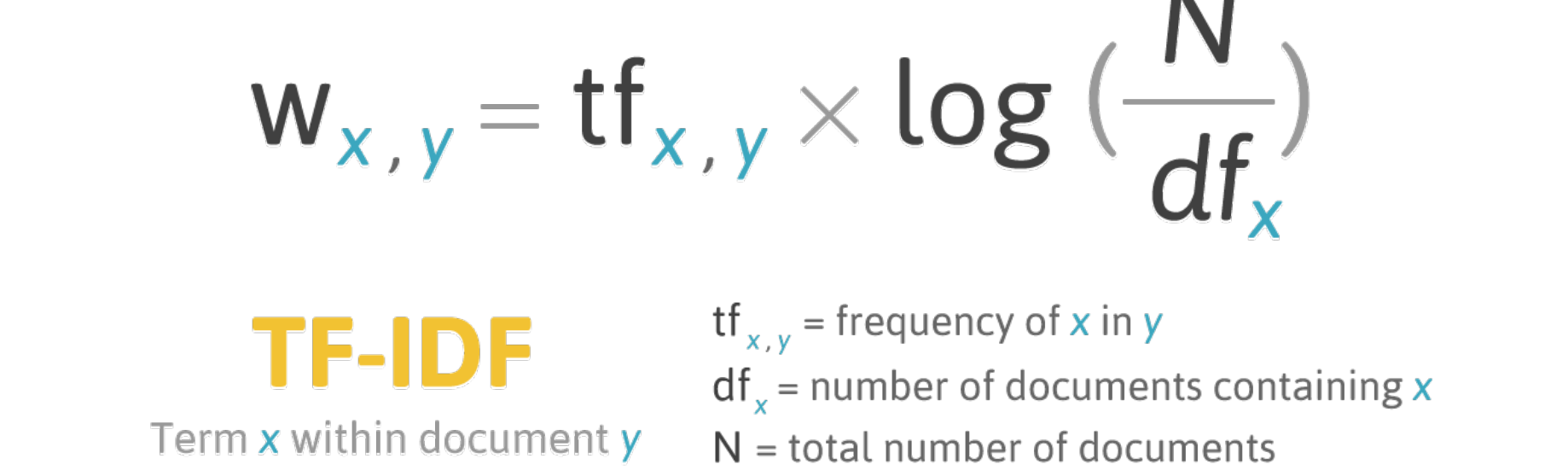
tf(x, y)는 단어 x가 문장 y에서 출연하는 빈도를 말한다.
IDF가 되는 log함수는 역빈도이며, 단어 x가 의미를 전달함에 있어서 어떤 중요도를 가지는가를 계산한다.
df(x)는 단어 x를 포함하는 문장 개수를 의미한다.
이에 관해 해석을 해보자면, 만약 하나의 단어가 많은 문장에서 출현한다면, 그 단어는 비교적 자주 사용하는 단어가 될 것이다.
따라서 어떤 문장에서 특수한 의미를 구별하는데는 큰 공헌을 못할 가능성이 높다.
그래서 가중치에 역빈도 패널티를 부여하는 것이다.
sents = [tokenized_sent1, tokenized_sent2]
print(sents)>> [['John', 'likes', 'to', 'watch', 'movies', '.', 'Mary', 'likes', 'movies', 'too', '.'], ['Mary', 'also', 'likes', 'to', 'watch', 'football', 'games', '.']]
def get_tf(word, tokenized_sent):
tf = 0
for token in tokenized_sent:
if token == word:
tf += 1
return tfimport mathdef get_idf(word, sents):
total_sent_num = len(sents)
df_num = 0
for sent in sents:
for token in sent:
if token == word:
df_num += 1
break
return math.log(total_sent_num / df_num)
print('sent1')
for word in word2idx:
tf = get_tf(word, tokenized_sent1)
idf = get_idf(word, sents)
print(word, tf * idf)
print('\nsent2')
for word in word2idx:
tf = get_tf(word, tokenized_sent2)
idf = get_idf(word, sents)
print(word, tf * idf)>> sent1
John 0.6931471805599453
likes 0.0
to 0.0
watch 0.0
movies 1.3862943611198906
. 0.0
Mary 0.0
likes 0.0
movies 1.3862943611198906
too 0.6931471805599453
. 0.0
sent2
Mary 0.0
also 0.6931471805599453
likes 0.0
to 0.0
watch 0.0
football 0.6931471805599453
games 0.6931471805599453
. 0.0
'Machine Learning > Basic' 카테고리의 다른 글
| 성능 평가 지표 (0) | 2020.07.27 |
|---|---|
| Categorical Feature (0) | 2020.07.25 |
| Feature Normalization (0) | 2020.07.14 |

